The entire IT infrastructure has been deployed on the PoliTo campus open-source cloud service based on Kubernetes technology.
Each campus photovoltaic plant differs in installed capacity, array configurations and monitoring infrastructure. For example, the “Cittadella” plant, which has the highest installed capacity at 600 kWp, is equipped with an electrical power sensor, a global irradiance sensor and a temperature sensor located on the roof near the inverter. By contrast, other plants such as “DIATI” (183 kWp) and “Aule P” (50 kWp) only have electrical power output sensors. To capture this heterogeneity of system configurations, the entire campus photovoltaic plants and monitoring infrastructure have been described using the Brick schema in a metadata model. This way, the logical and physical relationships are encoded in a standard and machine-readable way, allowing the automatic query of the datapoints needed for the analysis. Each photovoltaic plant is equipped with a data logger that samples, processes and stores data in a time-series database at 1-minute resolution. The time-series database was designed to support efficient data storage and retrieval of time-series data.
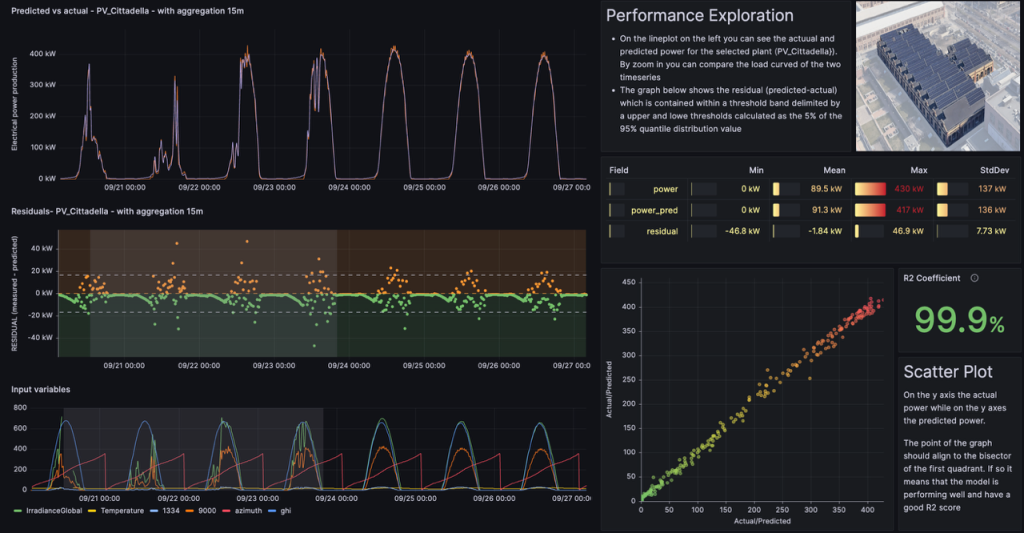
The algorithm leverages LSTM (Long Short-Term Memory) artificial neural networks to predict total electrical power production using external predictive variables such as zenith and azimuth angles, external air temperature and global horizontal irradiance.
The application can automatically assess if the metadata requirements (e.g., presence of a temperature sensor on the PV plant) are met by utilising the Brick metadata model of the PV plants. Additionally, the application is flexible enough to adapt to slightly different system configurations, accommodate missing sensors and remain agnostic to the naming conventions used for variables. For example, if a solar irradiance sensor is missing from a PV array, the application can substitute this variable with data from the campus weather station’s solar irradiance sensor without interrupting execution or causing compatibility issues.
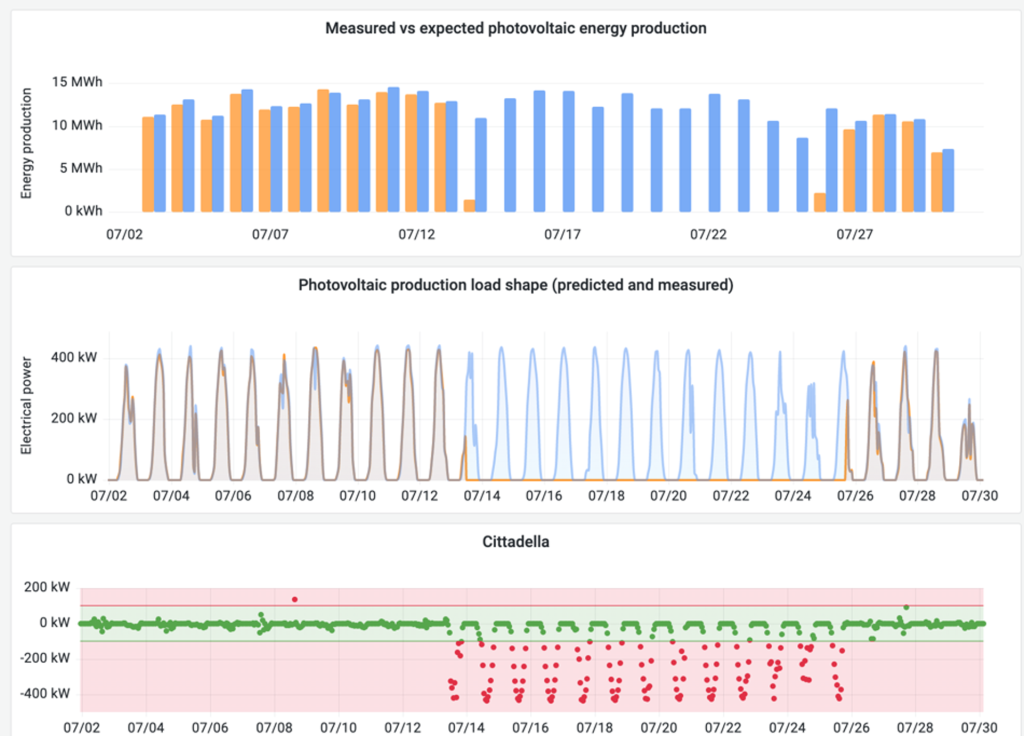
The development process for the anomaly detection algorithm was designed to be portable and scalable, allowing the methodological framework used for a single PV plant to be easily applied to other plants with minimal reconfiguration. Consequently, a machine-learning pipeline was deployed for all seven PV plants following two approaches. The initial setup involved training separate models for each plant using 12 months data from 2023 (from January to December) and testing with 1-month worth of data from January 2024. These models were then deployed via Docker containers: for every incoming measurement the models estimate the expected photovoltaic production, calculating residuals and performing threshold analysis to identify possible malfunctioning. To keep the models up-to-date, monthly retraining is performed the first day of the month by means of a 6-month sliding window (i.e. each 1st of the month the previous 6 months data are considered), ensuring they reflect recent data and disregard older data that may correspond to previous system configurations (e.g., post-maintenance or cleaning performance changes).
Forecast results are available to end users through a visualisation frontend, and alerts with possible maintenance suggestions are communicated via email notifications.